Illumina y BGI



Características
●Plataformas:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten y BGI-DNB-T7
●Modos de secuenciación:PE50, PE100, PE150, PE250
●Control de calidad de bibliotecas antes de la secuenciación.
●Entrega de datos de secuenciación y control de calidad:entrega de informes de control de calidad y datos sin procesar en formato fastq después de demultiplexar y filtrar lecturas Q30.
Ventajas del servicio
●Versatilidad de los servicios de secuenciación:el cliente puede optar por secuenciar por carril, celda de flujo o cantidad de datos.
●Versatilidad de plataformas:Las bibliotecas DNB se pueden transferir a plataformas Illumina
●Amplia experiencia en plataforma de secuenciación Illumina:con miles de proyectos cerrados con diversas especies.
●Entrega del informe de control de calidad de secuenciación:con métricas de calidad, precisión de los datos y rendimiento general del proyecto de secuenciación.
●Proceso de secuenciación maduro:con un corto tiempo de respuesta.
●Control de calidad riguroso: implementamos estrictos requisitos de control de calidad para garantizar la entrega de resultados consistentes de alta calidad.
Requisitos de muestra*
Secuenciación de carriles parciales
| Cantidad de datos (X) | Concentración (qPCR/nM) | Volumen |
| X ≤ 50 GB | ≥ 2 nM | ≥ 20 µl |
| 50 GB ≤ X < 100 GB | ≥ 3 nM | ≥ 20 µl |
| X ≥ 100 GB | ≥ 4 nM | ≥ 20 µl |
Carril único (Illumina)
| Plataforma | Concentración (qPCR/nM) | Volumen |
| HiSeq X Diez | ≥ 2 nM | ≥ 20 µl |
| NovaSeq 6000 SP | ≥ 1 nM | ≥ 25 µl |
| NovaSeq 6000 S4 | ≥ 1,5 nM | ≥ 25 µl |
| NovaSeqX | ≥ 1,5 nM | ≥ 25 µl |
| BGI-DNBSEQ-T7 | ≥ 1,5 nM | ≥ 25 µl |
Además de la concentración y la cantidad total, también se requiere un patrón de picos adecuado.
Comuníquese con nosotros si sus muestras no cumplen con los requisitos del material de partida.
Flujo de trabajo del servicio
control de calidad de la biblioteca

Secuenciación

Control de calidad de datos

Entrega del proyecto
Informe de control de calidad de la biblioteca
Se proporciona un informe sobre la calidad de la biblioteca antes de la secuenciación, la evaluación de la cantidad y la fragmentación de la biblioteca.
Informe de control de calidad de secuenciación
Tabla 1. Estadísticas sobre datos de secuenciación.
| ejemplo de identificacion | BMKID | Lecturas crudas | Datos brutos (pb) | Lecturas limpias (%) | Q20(%) | Q30(%) | CG(%) |
| C_01 | BMK_01 | 22.870.120 | 6.861.036.000 | 96,48 | 99,14 | 94,85 | 36,67 |
| C_02 | BMK_02 | 14.717.867 | 4.415.360.100 | 96.00 | 98,95 | 93,89 | 37.08 |
Figura 1. Distribución de calidad a lo largo de lecturas en cada muestra
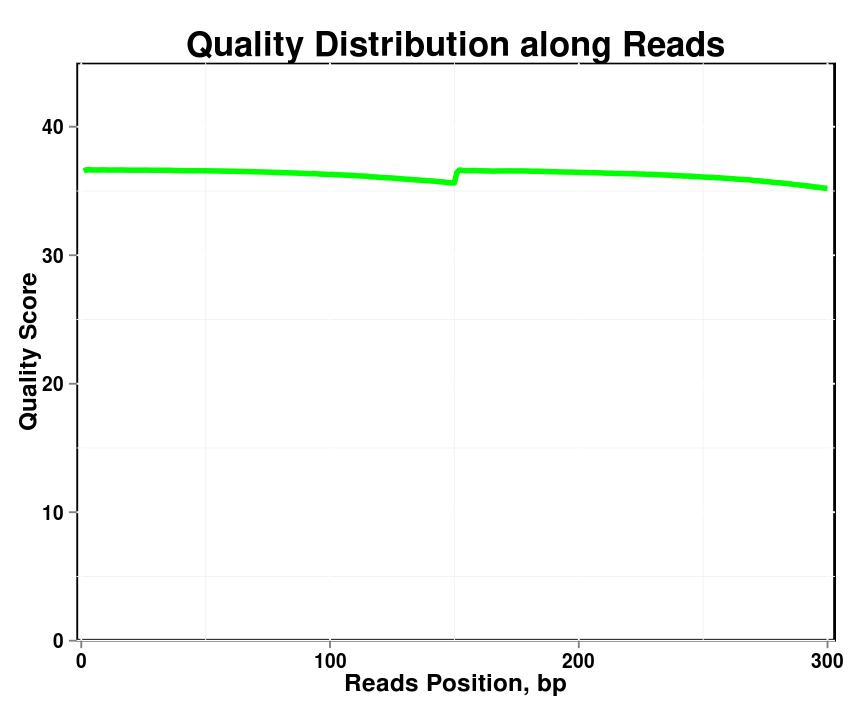
Figura 2. Distribución del contenido base
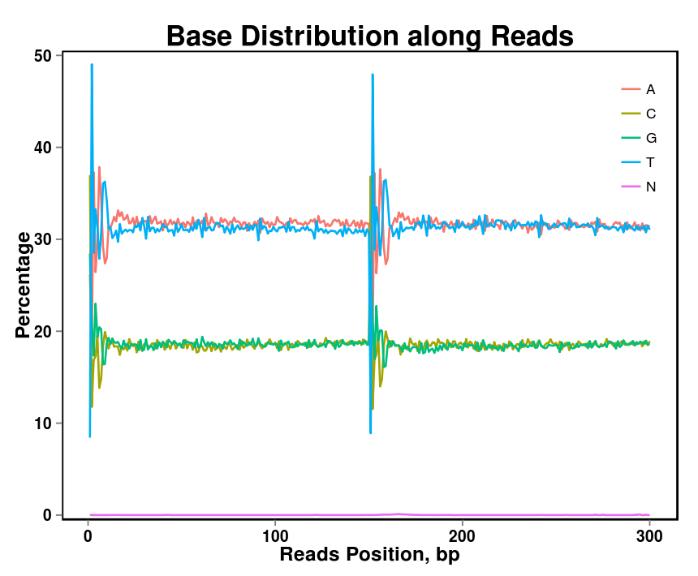
Figura 3. Distribución de contenidos leídos en datos de secuenciación.