

Secuenciación de ADN/ARN – Secuenciador de nanoporos


Detalles del servicio Características
| Plataforma | Tamaño de la biblioteca | Rendimiento de datos teóricos (por celda) | Precisión de base única | Aplicaciones |
| nanoporo | 8 Kb, 10 kb, 20 kb, ultralargo, ADNc-PCR | 70-90 Gb/celda | 85-92% | Llamada SV, De novo, Secuenciación completa, Iso-Seq, Anotación genética, Detección de metilación del ADN |
Ventajas del servicio
● Más de 5 años de experiencia en la plataforma de secuenciación PacBio con miles de proyectos cerrados con diversas especies.
● BMKGENE es socio oficial de Oxford Nanopore, con certificación de doble plataforma ARN/ADN.
● Existen modelos convencionales de secuenciadores con equipamiento completo y suficiente rendimiento de secuenciación.
● Basado en la plataforma Nanopore, más de 10 investigaciones de Denovo sobre animales y plantas han sido publicadas en revistas de renombre internacional.
Requisitos de muestra
| Tipo de ejemplo | Cantidad | Concentración (Qubit ®) | Volumen | Pureza | Otros |
| ADN genómico | Depende del requisito de datos | ≥20ng/μl | ≥15μl | DO260/280=1,7-2,2; OD260/230≥1,5; Pico claro a 260 nm, sin contaminaciones | La concentración debe medirse mediante Qubit y Qubit/Nanopore ≤ 2 |
| ARN total | ≥1,2μg | ≥100μg/μl | ≥15μl | DO260/280=1,7-2,5; OD260/230=0,5-2,5; sin contaminaciones | Valor RIN ≥7,5 |
Flujo de trabajo del servicio
preparación de la muestra
construcción de biblioteca

Secuenciación

Análisis de los datos

Entrega del proyecto
Evaluación de la calidad de los datos de la muestra de ADN.
Tabla 1. Estadísticas sobre datos limpios.
| BMKID | rawNumSeqNum | rawSumBase | cleanSeqNum | cleanSumBase | limpioN50Len | limpioN90Len | limpiarMeanLen | limpiarMaxLen | limpioMeanQual |
| ADN_BMK01 | 1.218.239 | 26.37 | 1.121.736 | 25,90 | 28.014 | 15.764 | 23.090 | 143,181 | 9 |
Evaluación de la calidad de los datos de la muestra de ARN
Tabla 1. Estadísticas sobre datos limpios.
| Nombre del archivo | Identificación del cliente | LeerNum | Númbase | N50 | Longitud media | Longitud máxima | Puntuación Q media |
| ARN_BMK001 | C2 | 8.947.708 | 4.047.230.083 | 398 | 452 | 129,227 | Q12 |
Figura 1. Distribución de longitud de lectura
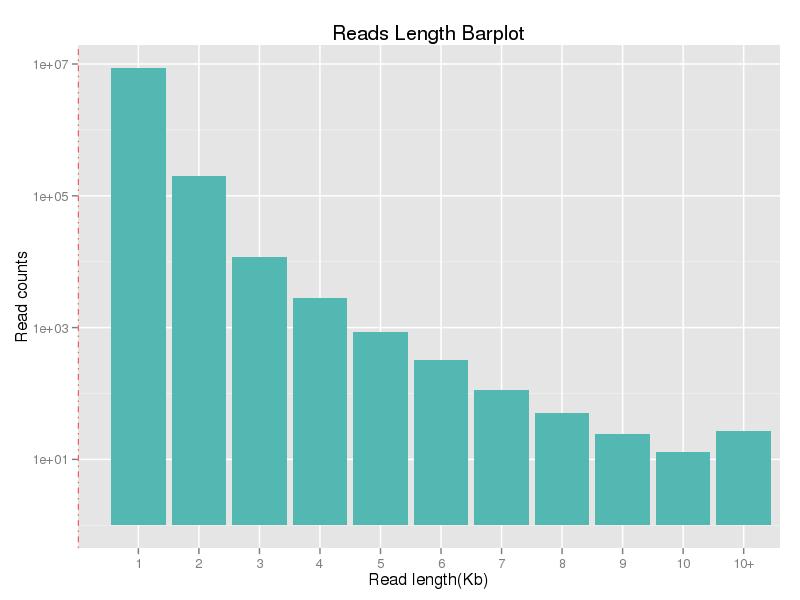
Figura 2. Distribución del puntaje de calidad de datos limpios
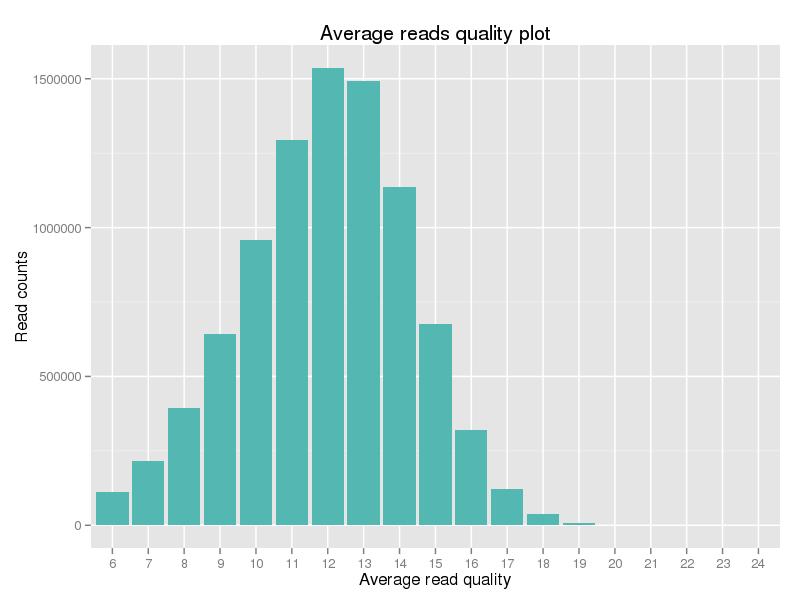
Figura 3. Distribución de puntuación de longitud y calidad de datos limpios






