

RESEQUENZIAMENTO DELL'INTERO GENOMA

Varianti strutturali nella popolazione cinese e loro impatto su fenotipi, malattie e adattamento della popolazione
Nanoporo |PacBio |Risequenziamento dell'intero genoma |Chiamata di variazione strutturale
In questo studio, il sequenziamento di Nanopore PromethION è stato fornito da Biomarker Technologies.
Punti salienti
In questo studio, un panorama complessivo di variazioni strutturali (SV) nel genoma umano è stato rivelato con l'aiuto del sequenziamento a lunga lettura sulla piattaforma Nanopore PromethION, che approfondisce la comprensione delle SV nei fenotipi, nelle malattie e nell'evoluzione.
Design sperimentale
Campioni: leucociti del sangue periferico di 405 individui cinesi non imparentati (206 maschi e 199 femmine) con 68 misurazioni fenotipiche e cliniche.Tra tutti gli individui, le regioni ancestrali di 124 individui erano province del Nord, quelle di 198 individui erano del Sud, 53 erano del Sud-Ovest e 30 non erano conosciute.
Strategia di sequenziamento: sequenziamento a lunga lettura dell'intero genoma (LRS) con letture Nanopore 1D e letture PacBio HiFi.
Piattaforma di sequenziamento: Nanopore PromethION;PacBioSequel II
Chiamata di variazione della struttura
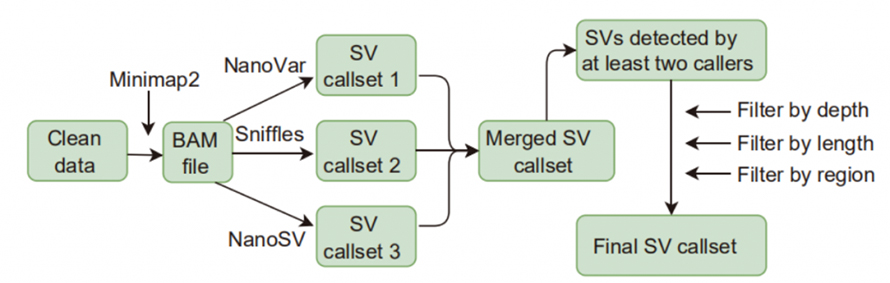
Figura 1. Flusso di lavoro delle chiamate e dei filtri SV
Traguardi principali
Scoperta e validazione delle variazioni della struttura
Set di date nanopore: in totale 20,7 Tb di letture pulite generate sulla piattaforma di sequenziamento PromethION, ottenendo una media di 51 Gb di dati per campione, ca.17 volte in profondità.
Allineamento del genoma di riferimento (GRCh38): è stato raggiunto un tasso di mappatura medio del 94,1%.Il tasso di errore medio (12,6%) era simile a quello di un precedente studio di benchmarking (12,6%) (Figura 2b e 2c)
Chiamata di variazione della struttura (SV): i chiamanti SV applicati in questo studio includevano Sniffles, NanoVar e NanoSV.Gli SV ad alta confidenza sono stati definiti come SV identificati da almeno due chiamanti e hanno superato i filtraggi su profondità, lunghezza e regione.
In ciascun campione è stata identificata una media di 18.489 SV ad alta confidenza (da 15.439 a 22.505).(Figura 2d, 2e e 2f)
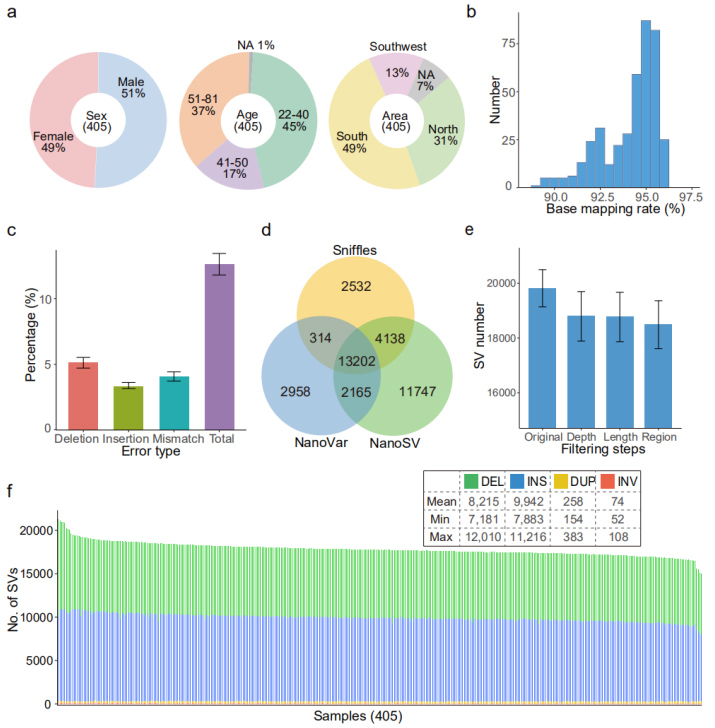
Figura 2. Panorama generale delle SV identificate dal set di dati Nanopore
Convalida da parte di PacBio: gli SV identificati in un campione (HG002, bambino) sono stati convalidati da un set di dati HiFi PacBio.Il tasso complessivo di false scoperte (FDR) è stato del 3,2%, a dimostrazione di un'identificazione SV relativamente affidabile mediante letture Nanopore.
SV non ridondanti e caratteristiche genomiche
SV non ridondanti: un set di 132.312 SV non ridondanti è stato ottenuto unendo gli SV in tutti i campioni, che include 67.405 DEL, 60.182 INS, 3.956 DUP e 769 INV.(Figura 3a)
Confronto con i set di dati SV esistenti: questo set di dati è stato confrontato con il set di dati TGS o NGS pubblicato.Tra i quattro set di dati confrontati, LRS15, che è anche l'unico set di dati della piattaforma di sequenziamento a lettura lunga (PacBio), ha condiviso le maggiori sovrapposizioni con questo set di dati.Inoltre, il 53,3% (70.471) dei SV in questo set di dati sono stati segnalati per la prima volta.Esaminando ciascun tipo di SV, il numero di INS recuperati con set di dati di sequenziamento a lettura lunga era molto maggiore rispetto al resto di quelli a lettura breve, indicando che il sequenziamento a lettura lunga è particolarmente efficiente nel rilevamento degli INS.(Figure 3b e 3c)
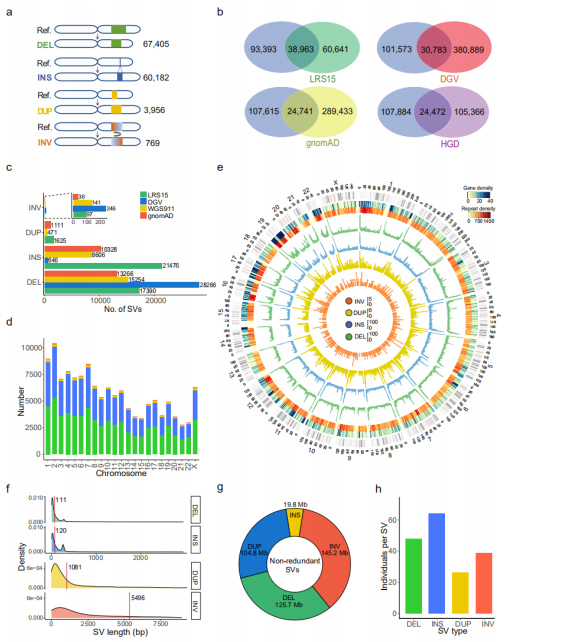
Figura 3. Proprietà degli SV non ridondanti per ciascun tipo di SV
Caratteristiche genomiche: il numero di SV è stato trovato significativamente correlato alla lunghezza del cromosoma.La distribuzione di geni, ripetizioni, DEL (verde), INS (blu), DUP (giallo) e INV (arancione) è stata visualizzata su un diagramma Circos, dove è stato osservato un aumento generale di SV all'estremità dei bracci cromosomici.(Figura 3d e 3e)
Lunghezza degli SV: le lunghezze degli INS e dei DEL sono risultate significativamente più brevi di quelle dei DUP e degli INV, che concordavano con quelle identificate dal set di dati PacBio HiFi.La lunghezza di tutti gli SV identificati ammontava a 395,6 Mb, che occupavano il 13,2% dell'intero genoma umano.Gli SV influenzavano in media 23,0 Mb (circa lo 0,8%) del genoma per individuo.(Figura 3f e 3g)
Impatti funzionali, fenotipici e clinici delle SV
SV di perdita di funzione prevista (pLoF): gli SV pLoF sono stati definiti come SV che interagivano con CDS, dove i nucleotidi codificanti venivano eliminati o gli ORF venivano alterati.In totale sono stati annotati 1.929 SV pLoF che influenzano CDS di 1.681 geni.All’interno di questi, 38 geni hanno evidenziato il “legame con i recettori delle immunoglobuline” nell’analisi di arricchimento GO.Questi SV pLoF sono stati ulteriormente annotati rispettivamente da GWAS, OMIM e COSMIC.(Figure 4a e 4b)
SV fenotipicamente e clinicamente rilevanti: un certo numero di SV nel set di dati dei nanopori ha dimostrato di essere fenotipicamente e clinicamente rilevanti.In tre individui è stata identificata una rara DEL eterozigote di 19,3 kb, nota per causare alfa-talassemia, che disfunzionava i geni della subunità alfa 1 e 2 dell'emoglobina (HBA1 e HBA2).Un altro DEL di 27,4 kb sul gene che codifica la subunità beta dell'emoglobina (HBB) è stato identificato in un altro individuo.Questa SV era nota per causare gravi emoglobinopatie.(Figura 4c)
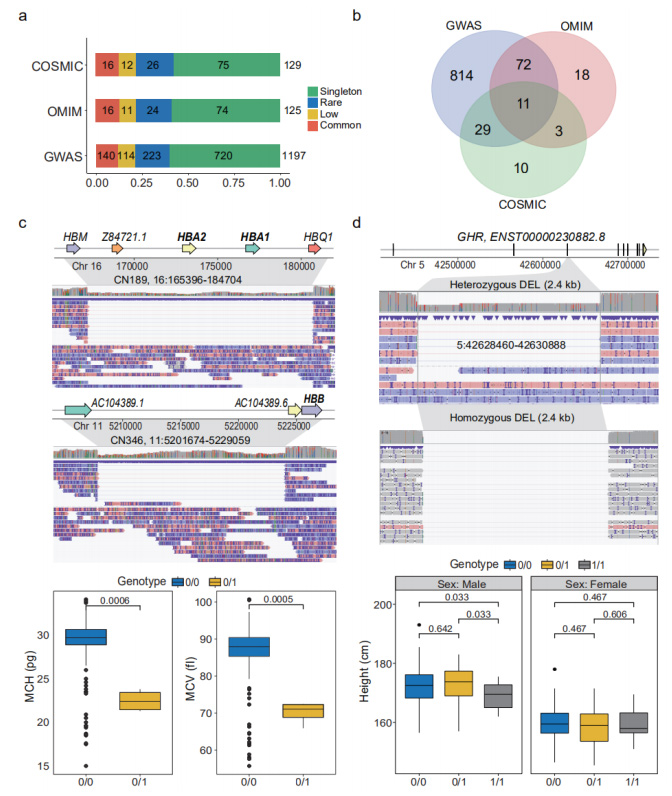
Figura 4. SV pLoF associati a fenotipi e malattie
Un DEL comune di 2,4 kb è stato osservato in 35 portatori omozigoti e 67 eterozigoti, che copre la regione completa del 3° esone del recettore dell'ormone della crescita (GHR).I portatori omozigoti sono risultati significativamente più bassi di quelli eterzigoti (p=0,033).(Figura 4d)
Inoltre, questi SV sono stati elaborati per studi sull’evoluzione della popolazione tra due gruppi regionali: Cina settentrionale e meridionale.Sono stati trovati SV significativamente differenziali distribuiti su Chr 1, 2, 3, 6,10,12,14 e 19, all'interno dei quali, quelli superiori erano associati a regioni immunitarie, come IGH, MHC, ecc. È ragionevole ipotizzare che il la differenziazione in questi SV può essere dovuta alla deriva genetica e all'esposizione a lungo termine a diversi ambienti per le sottopopolazioni in Cina.
Riferimento
Wu, Zhikun et al."Varianti strutturali nella popolazione cinese e il loro impatto su fenotipi, malattie e adattamento della popolazione".bioRxiv(2021).
Novità e punti salienti mira a condividere gli ultimi casi di successo con Biomarker Technologies, catturando nuovi risultati scientifici e tecniche importanti applicate durante lo studio.
Orario di pubblicazione: 06-gennaio-2022