NGS-mRNA(Riferimento)
Il trascrittoma è il collegamento tra l'informazione genetica genomica e il proteoma della funzione biologica.La regolazione del livello trascrizionale è la modalità di regolazione degli organismi più importante e più ampiamente studiata.Il sequenziamento del trascrittoma può sequenziare il trascrittoma in qualsiasi momento o in qualsiasi condizione, con una risoluzione accurata per un singolo nucleotide. Può riflettere dinamicamente il livello di trascrizione genetica, identificare e quantificare simultaneamente trascrizioni rare e normali e fornire informazioni strutturali di trascrizioni specifiche del campione.
Attualmente, la tecnologia di sequenziamento del trascrittoma è stata ampiamente utilizzata in agronomia, medicina e altri campi di ricerca, tra cui la regolamentazione dello sviluppo di animali e piante, l'adattamento ambientale, l'interazione immunitaria, la localizzazione dei geni, l'evoluzione genetica delle specie e il rilevamento di tumori e malattie genetiche.
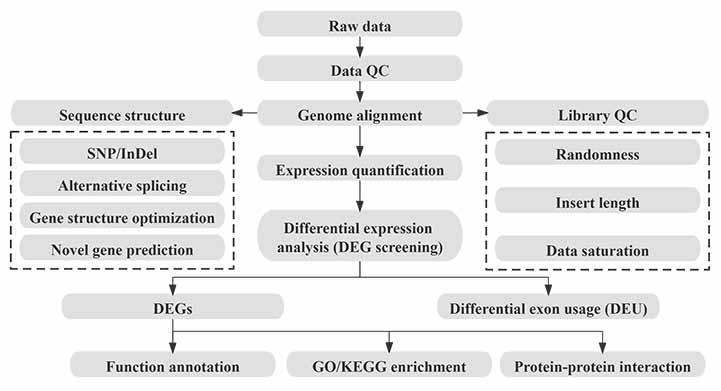
Bioinformatica
Flusso di lavoro della bioinformatica