

MÉTAGÉNOMIQUE

Génomes bactériens complets et fermés issus de microbiomes grâce au séquençage des nanopores
Séquençage des nanopores |Métagénomique |MAG |Circularisation du génome bactérien |Microbiote intestinal
Points forts
1. Une nouvelle méthode pour extraire de longs fragments d'ADN a été présentée dans cette étude, qui a permis d'extraire un microgramme d'ADN HMW pur adapté au séquençage à lecture longue à partir de 300 mg de selles.
2.Un flux de travail d'assemblage, le tour, a été introduit dans cette étude, dans lequel les MAG étaient assemblés par des lectures longues et corrigés par des lectures courtes.
3.Le tour a été évalué par un mélange simulé.7 bactéries sur 12 ont été assemblées avec succès en contigs simples et 3 ont été assemblées en quatre contigs ou moins.
4.Le tour a ensuite été appliqué à des échantillons de selles, qui ont généré 20 génomes circularisés, dont Prevotella copri et le candidat Cibiobacter sp., connus pour être riches en éléments génétiques mobiles.
Réalisation principale
Protocole d'extraction de l'ADN HWM
Les études métagénomiques intestinales basées sur le séquençage à lecture longue ont longtemps souffert de la difficulté d'extraire l'ADN de haut poids moléculaire (HMW) des selles.Dans cette étude, un protocole d’extraction basé sur des enzymes a été introduit pour éviter un cisaillement important par battage de billes dans les méthodes traditionnelles.Comme le montre la figure suivante, les échantillons ont d'abord été traités avec un cocktail d'enzymes, notamment une enzyme lytique, du MetaPolyzyme, etc., pour dégrader les parois cellulaires.L'ADN libéré a été extrait par un système phénol-chloroforme, suivi d'une digestion par la protéinase K et la RNase A, d'une purification sur colonne et d'une sélection de la taille du SPRI.Cette méthode a réussi à produire des microgrammes d’ADN HMW à partir de 300 m de selles, ce qui répond aux exigences de séquençage à lecture longue en termes de qualité et de quantité.
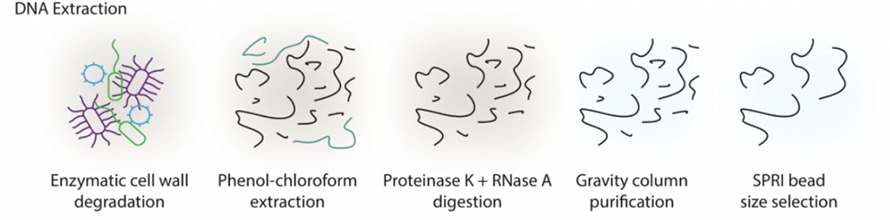
Figure 1. Schéma d'extraction de l'ADN HWM
Déroulement du schéma du tour
Comme décrit dans la figure suivante, Lathe contient le processus existant de processus d'appel de base brut utilisant Guppy.Deux assemblages à lecture longue sont ensuite produits séparément par Flye et Canu, suivis d'une détection et d'un retrait des erreurs d'assemblage.Les deux sous-ensembles sont fusionnés avec quickmerge.Lors de la fusion, la circularisation des grands assemblages au niveau de la mégabase est ensuite vérifiée.Par la suite, l'affinement du consensus sur ces assemblées est traité avec de courtes lectures.Les génomes bactériens assemblés finaux sont traités pour la détection et l'élimination finales des erreurs d'assemblage.
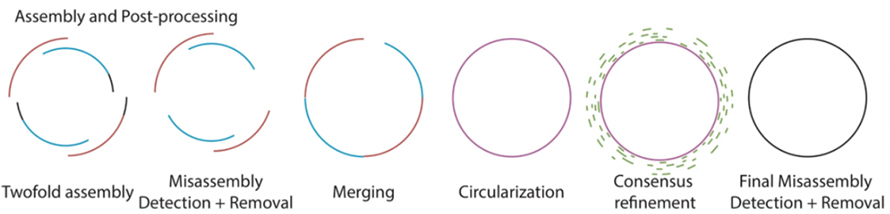
Figure 2. Schéma de déroulement de l'assemblage du tour
Évaluation du tour avec un mélange de bactéries factices
Un mélange standard ATCC de 12 espèces comprenant à la fois des bactéries Gram-positives et Gram-négatives a été utilisé pour évaluer les performances de la plate-forme de séquençage des nanopores et du tour dans l'assemblage MAG.Un total de 30,3 Go de données ont été générés par la plateforme nanopore avec un N50 de 5,9 Ko.Le tour a largement amélioré l'assemblage N50, de 1,6 à 4 fois par rapport aux autres outils d'assemblage à lecture longue et de 2 à 9 fois par rapport aux outils d'assemblage hybrides.Sur 12 génomes bactériens, sept ont été assemblés en contigs uniques (Figure 3. Circos avec point noir).Trois autres ont été assemblés en quatre contigs ou moins, dans lesquels l'assemblage le plus incomplet contenait 83 % du génome dans un seul contig.
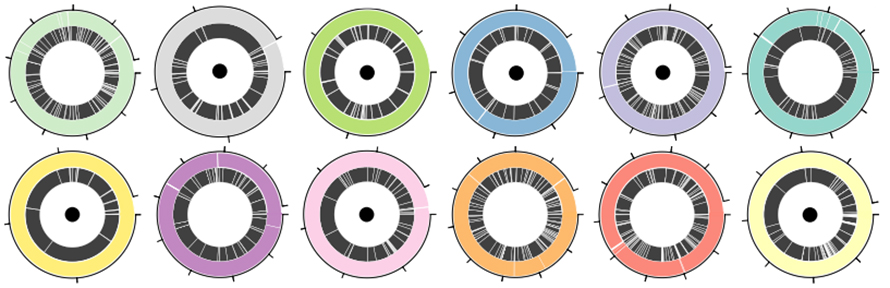
Figure 3. Assemblages du génome dans un mélange bactérien défini de 12 espèces
Application de Lathe dans des échantillons de selles
Cette méthode a ensuite été appliquée à des échantillons de selles humaines afin de comparer l’identification de l’organisme et la contiguïté de l’assemblage aux méthodes existantes, à l’analyse basée sur le cloud de lecture et la lecture courte.À partir des trois échantillons impliqués, la nouvelle extraction enzymatique a donné au moins 1 μg pour 300 mg de masse d’entrée.Le séquençage nanopore de ces ADN HMW a généré des lectures longues avec N50 de 4,7 kb, 3,0 kb et 3,0 kb respectivement.Notamment, la méthode actuelle a montré un grand potentiel en matière de détection microbienne par rapport aux méthodes existantes.Une diversité alpha au niveau des espèces relativement plus élevée a été montrée ici par rapport aux nuages de lecture courte et de lecture.De plus, tous les genres issus d’analyses à lecture courte, même les organismes Gram-positifs typiquement résistants à la lyse, ont été récupérés par cette méthode.
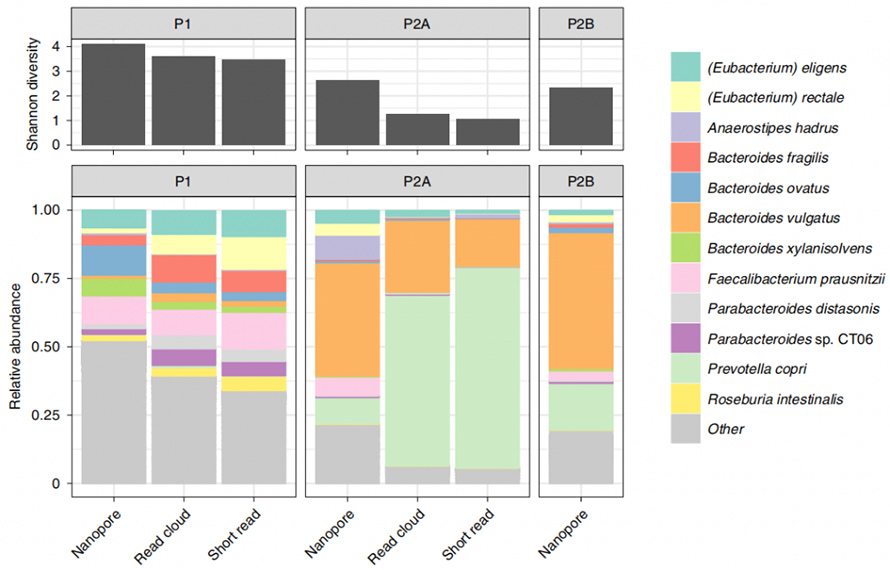
Figure 4. Diversité alpha et composants taxanomiques déterminés par les méthodes Nanopore, lecture courte et lecture-nuage
Le tour a produit un N50 d'assemblage complet beaucoup plus long que l'assemblage de lecture courte et de nuage de lecture, malgré une entrée de données brutes trois à six fois inférieure.Les ébauches de génomes ont été produites par regroupement de contigs, dans lequel les ébauches ont été classées en « haute qualité » ou « partielles » en fonction de l'exhaustivité, de la contamination, des gènes centraux à copie unique, etc. L'assemblage à lecture longue a montré une contiguïté beaucoup plus élevée à un coût inférieur à celui des génomes. à la lecture courte et à la lecture dans le cloud.
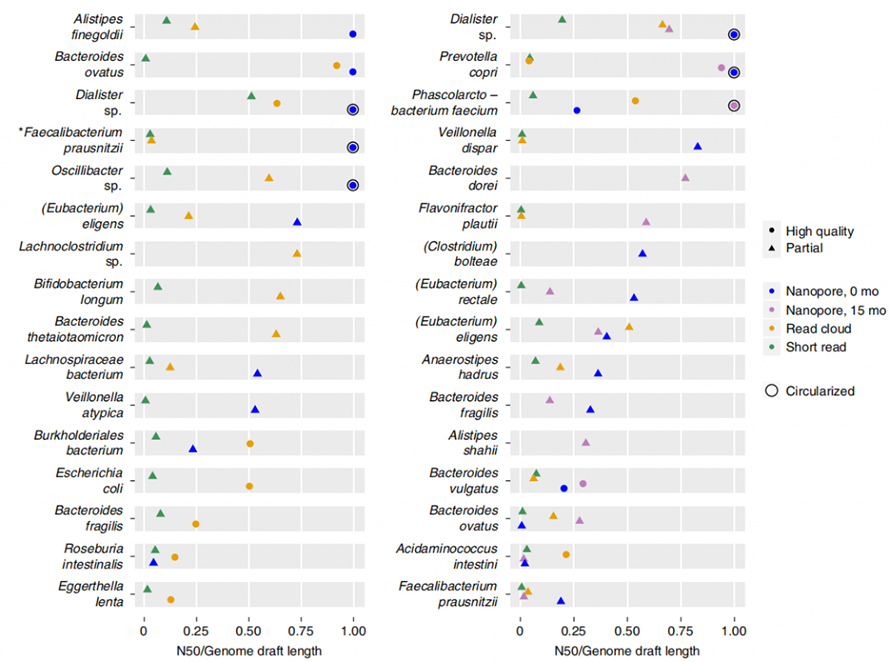
Figure 5. Contiguïté de l'assemblage par organisme de chaque méthode
De plus, l’approche d’assemblage actuelle est capable de produire des génomes fermés et circulaires.Dans les échantillons de selles, huit génomes à contig unique de haute qualité ont été assemblés et cinq d’entre eux ont atteint une circularisation précise.L’approche à lecture longue a également montré une capacité impressionnante à résoudre les éléments répétitifs du génome.CirculariséP. copriLe génome a été généré par cette approche, connue pour contenir un degré élevé de répétition de séquences.Le meilleur assemblage de ce génome par lecture courte et cloud de lecture n'a jamais dépassé N50 de 130 Ko, même avec une profondeur de couverture de 4800X.Ces éléments à nombre de copies élevé ont été entièrement résolus par une approche de lecture longue, qui se trouvait souvent aux points de rupture des assemblys à lecture courte ou en nuage de lecture.Un autre génome fermé a été rapporté dans cette étude, qui serait un membre du génome récemment décrit.Cibiobactérieclade.Cinq phages putatifs ont été identifiés dans cet assemblage fermé, allant de 8,5 à 65,9 kb.
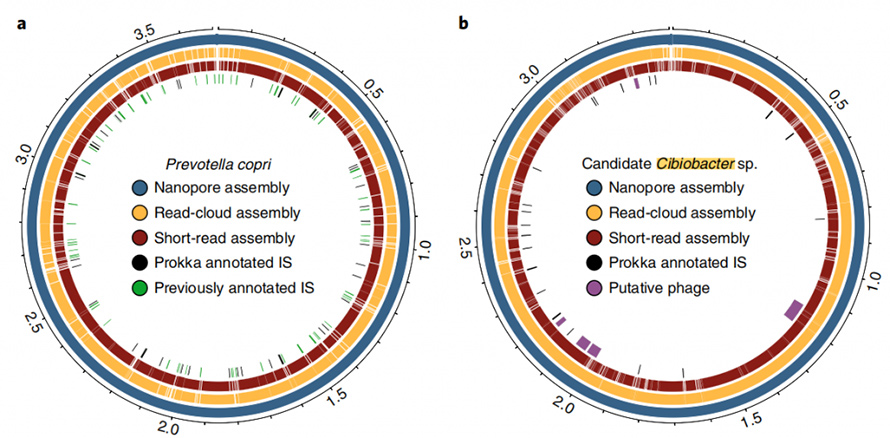
Figure 6. Diagramme Circos des génomes fermés de P.copri et Cibiobacter sp.
Référence
Moss, EL, Maghini, DG et Bhatt, AS (2020).Génomes bactériens complets et fermés issus de microbiomes grâce au séquençage des nanopores.Biotechnologie naturelle,38(6), 701-707.
Technologie et points forts vise à partager les applications réussies les plus récentes de différentes technologies de séquençage à haut débit dans divers domaines de recherche ainsi que des idées brillantes en matière de conception expérimentale et d'exploration de données.
Heure de publication : 07 janvier 2022