

METAGENOMIK

Vollständige, geschlossene Bakteriengenome aus Mikrobiomen mittels Nanoporensequenzierung
Nanoporensequenzierung |Metagenomik |MAGs |Zirkularisierung des Bakteriengenoms |Darmmikroben
Höhepunkte
1. In dieser Studie wurde eine neuartige Methode zur Extraktion langer DNA-Fragmente vorgestellt, mit der aus 300 mg Stuhl Mikrogramm reine HMW-DNA extrahiert werden konnte, die für die Long-Read-Sequenzierung geeignet ist
2. In dieser Studie wurde ein Montage-Workflow, Lathe, eingeführt, bei dem MAGs durch lange Lesevorgänge zusammengesetzt und durch kurze Lesevorgänge korrigiert wurden.
3. Die Drehmaschine wurde durch Scheinmischung bewertet.7 von 12 Bakterien wurden erfolgreich zu einzelnen Contigs zusammengestellt und 3 wurden zu vier oder weniger Contigs zusammengestellt.
4. Die Drehmaschine wurde weiter auf Stuhlproben angewendet, wodurch 20 zirkularisierte Genome erzeugt wurden, darunter Prevotella copri und der Kandidat Cibiobacter sp., die für ihren Reichtum an mobilen genetischen Elementen bekannt waren.
Wichtigster Erfolg
Extraktionsprotokoll für HWM-DNA
Langfristige, auf Sequenzierung basierende Studien zur Darmmetagenomik leiden seit langem unter der Schwierigkeit, DNA mit hohem Molekulargewicht (HMW) aus Stuhl zu extrahieren.In dieser Studie wurde ein enzymbasiertes Extraktionsprotokoll eingeführt, um eine übermäßige Scherung durch Perlenschlagen bei herkömmlichen Methoden zu vermeiden.Wie in der folgenden Abbildung dargestellt, wurden die Proben zunächst mit einem Enzymcocktail, einschließlich lytischem Enzym, MetaPolyzyme usw., behandelt, um Zellwände abzubauen.Freigesetzte DNA wurde mit einem Phenol-Chloroform-System extrahiert, gefolgt von Proteinase K- und RNase A-Verdau, säulenbasierter Reinigung und SPRI-Größenauswahl.Mit dieser Methode gelang es, Mikrogramm HMW-DNA aus 300 m Stuhl zu gewinnen, was sowohl qualitativ als auch quantitativ die Anforderungen der Long-Read-Sequenzierung erfüllt.
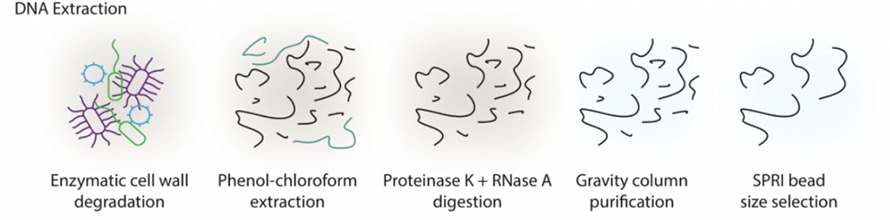
Abbildung 1. HWM-DNA-Extraktionsschema
Schemaablauf der Drehmaschine
Wie in der folgenden Abbildung beschrieben, enthält Lathe den vorhandenen Prozess des rohen Basecalling-Prozesses unter Verwendung von Guppy.Anschließend werden von Flye und Canu zwei lang gelesene Baugruppen separat hergestellt, gefolgt von der Erkennung und Entfernung fehlerhafter Baugruppen.Die beiden Unterbaugruppen werden mit Quickmerge zusammengeführt.Beim Zusammenführen werden große Baugruppen auf Megabase-Ebene dann auf Zirkularisierung überprüft.Anschließend wird die Konsensverfeinerung dieser Baugruppen mit kurzen Lesevorgängen durchgeführt.Die fertig zusammengesetzten Bakteriengenome werden zur endgültigen Erkennung und Entfernung von Fehlassemblierungen verarbeitet.
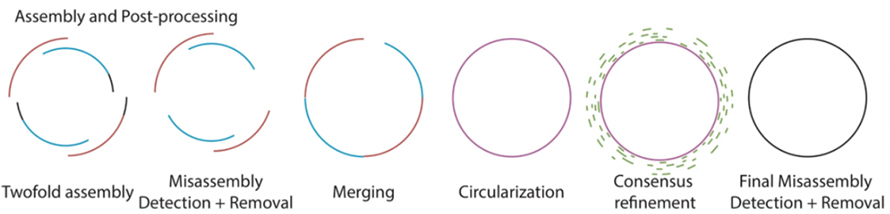
Abbildung 2. Schematischer Ablauf der Drehmaschinenmontage
Bewertung einer Drehmaschine mit Scheinbakterienmischung
Zur Bewertung der Leistung der Nanoporen-Sequenzierungsplattform und der Drehmaschine bei der MAG-Montage wurde eine Standard-ATCC-12-Spezies-Mischung verwendet, die sowohl grampositive als auch gramnegative Bakterien umfasste.Insgesamt wurden 30,3 GB Daten von der Nanoporenplattform mit einem N50 von 5,9 kb generiert.Die Drehmaschine verbesserte die Montage N50 im Vergleich zu anderen Langlese-Montagewerkzeugen um das 1,6- bis 4-Fache und im Vergleich zu Hybrid-Montagewerkzeugen um das 2- bis 9-Fache.Von 12 Bakteriengenomen wurden sieben zu einzelnen Contigs zusammengesetzt (Abbildung 3. Circos mit schwarzem Punkt).Drei weitere wurden zu vier oder weniger Contigs zusammengesetzt, wobei die unvollständigste Anordnung 83 % des Genoms in einem einzelnen Contig enthielt.
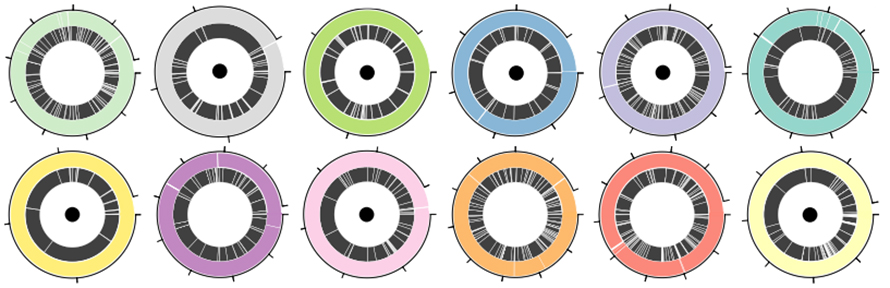
Abbildung 3. Genomanordnungen in einer definierten Bakterienmischung aus 12 Arten
Anwendung von Lathe in Stuhlproben
Diese Methode wurde weiter auf menschliche Stuhlproben angewendet, um die Organismenidentifizierung und Zusammengehörigkeitskontiguität mit bestehenden Methoden, Read-Cloud- und Short-Read-basierten Analysen, zu vergleichen.Aus den drei beteiligten Proben ergab die neue enzymbasierte Extraktion mindestens 1 μg pro 300 mg Einsatzmasse.Die Nanoporensequenzierung dieser HMW-DNA erzeugte Long-Reads mit N50 von 4,7 kb, 3,0 kb bzw. 3,0 kb.Insbesondere zeigte die vorliegende Methode im Vergleich zu bestehenden Methoden ein großes Potenzial für den Nachweis von Mikroben.Hier wurde im Vergleich zu Short-Read und Read-Cloud eine relativ höhere Alpha-Diversität auf Artenebene gezeigt.Darüber hinaus wurden mit dieser Methode alle Gattungen aus der Short-Read-Analyse gewonnen, sogar typischerweise lyseresistente grampositive Organismen.
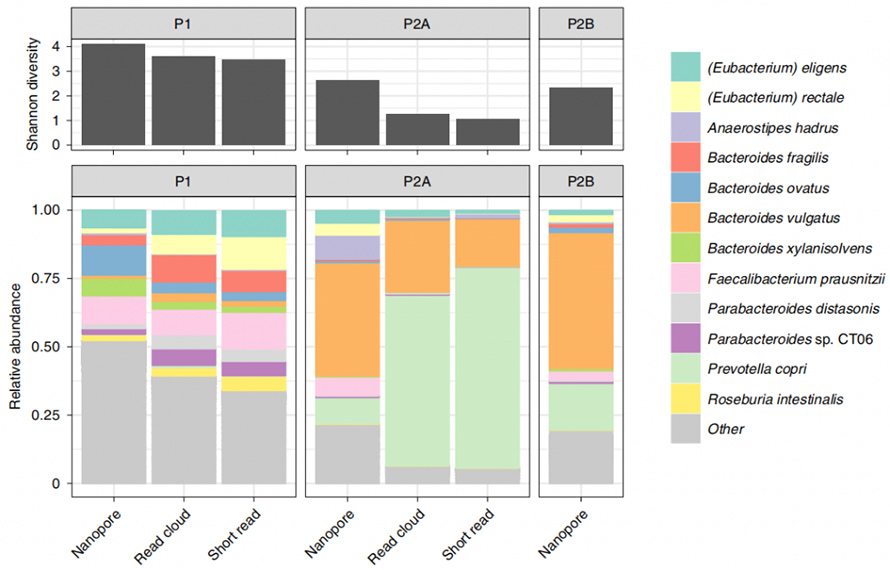
Abbildung 4. Alpha-Diversität und taxonomische Komponenten, bestimmt durch Nanopore-, Short-Read- und Read-Cloud-Methoden
Die Drehbank lieferte eine viel längere Gesamtbaugruppe N50 als die Kurzlese- und Lesewolkenbaugruppe, trotz einer drei- bis sechsfach geringeren Eingabe von Rohdaten.Entwurfsgenome wurden durch Contig-Binning erstellt, bei dem die Entwürfe basierend auf Vollständigkeit, Kontamination, Einzelkopie-Kerngenen usw. in „hochwertige“ oder „teilweise“ klassifiziert wurden. Long-Read-Assembly zeigte im Vergleich dazu eine viel höhere Kontiguität bei geringeren Kosten zu Short-Read und Read-Cloud.
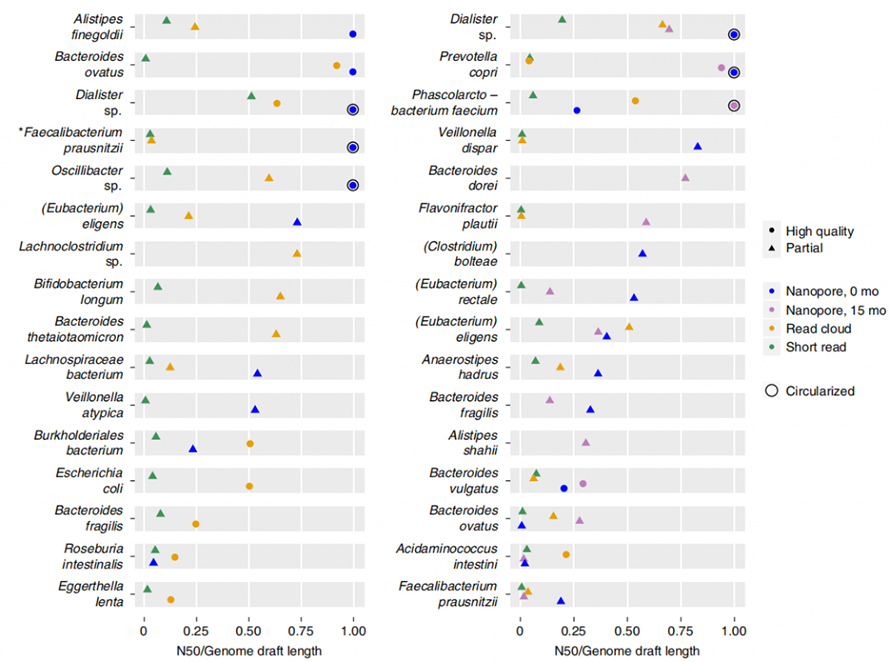
Abbildung 5. Kontiguität der einzelnen Methoden pro Organismus
Darüber hinaus ist der vorliegende Assemblierungsansatz in der Lage, geschlossene, kreisförmige Genome zu ergeben.In den Stuhlproben wurden acht hochwertige Single-Contig-Genome zusammengesetzt und fünf davon erreichten eine genaue Zirkularisierung.Der Long-Read-Ansatz zeigte auch eine beeindruckende Fähigkeit, sich wiederholende Elemente in Genomen aufzulösen.ZirkularisiertP. copriDas Genom wurde durch diesen Ansatz erzeugt, der bekanntermaßen ein hohes Maß an Sequenzwiederholungen enthält.Die beste Assemblierung dieses Genoms durch Short-Read und Read-Cloud überschritt nie N50 von 130 kb, selbst bei einer Abdeckungstiefe von 4800X.Diese Elemente mit hoher Kopienzahl wurden vollständig durch den Long-Read-Ansatz aufgelöst, der häufig an Bruchstellen von Short-Read- oder Read-Cloud-Assemblys zu finden war.In dieser Studie wurde über ein weiteres geschlossenes Genom berichtet, von dem angenommen wurde, dass es sich um ein Mitglied der kürzlich beschriebenen handeltCibiobacterKlade.In dieser geschlossenen Anordnung wurden fünf mutmaßliche Phagen mit einer Größe von 8,5 bis 65,9 kb identifiziert.
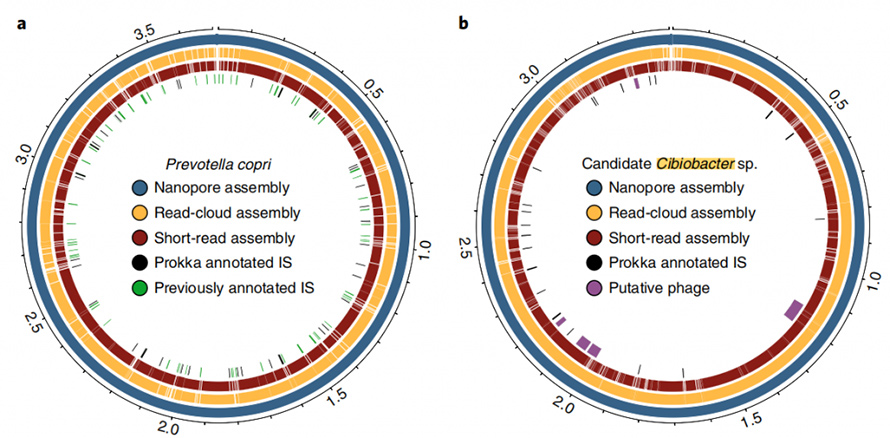
Abbildung 6. Circos-Diagramm der geschlossenen Genome von P.copri und Cibiobacter sp.
Referenz
Moss, EL, Maghini, DG, & Bhatt, AS (2020).Vollständige, geschlossene Bakteriengenome aus Mikrobiomen mittels Nanoporensequenzierung.Naturbiotechnologie,38(6), 701-707.
Technik und Highlights Ziel ist es, die neuesten erfolgreichen Anwendungen verschiedener Hochdurchsatz-Sequenzierungstechnologien in verschiedenen Forschungsbereichen sowie brillante Ideen im experimentellen Design und beim Data Mining zu teilen.
Zeitpunkt der Veröffentlichung: 07.01.2022