NGS-ARNm (Referencia)
El transcriptoma es el vínculo entre la información genética genómica y el proteoma de la función biológica.La regulación del nivel transcripcional es el modo de regulación de los organismos más importante y más ampliamente estudiado.La secuenciación del transcriptoma puede secuenciar el transcriptoma en cualquier momento o bajo cualquier condición, con una resolución precisa de un solo nucleótido. Puede reflejar dinámicamente el nivel de transcripción genética, identificar y cuantificar simultáneamente transcripciones raras y normales, y proporcionar la información estructural de transcripciones específicas de muestra.
En la actualidad, la tecnología de secuenciación de transcriptomas se ha utilizado ampliamente en agronomía, medicina y otros campos de investigación, incluida la regulación del desarrollo de animales y plantas, la adaptación ambiental, la interacción inmune, la localización de genes, la evolución genética de especies y la detección de tumores y enfermedades genéticas.
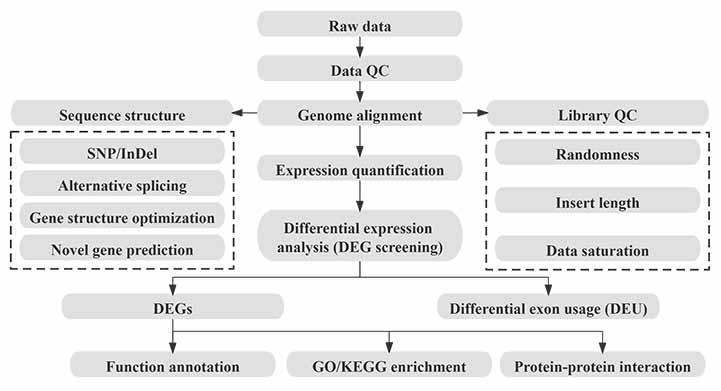
Bioinformática
Flujo de trabajo de bioinformática